
Understanding causation instead of mere correlation is one of the hot topics within the AI community. Prof Judea Pearl’s breakthrough work on causality won him the Turing Award in 2011 and two economists shared the Nobel Prize in 2021 for their work on the topic. However, causal reasoning hasn’t yet been widely applied to business problems. The Geminos Causeway platform is designed to address this challenge, thereby bringing the power of causality to everyday AI solutions development, with a particular focus on digital transformation projects.
When using causality for digital transformation, we need to follow a series of steps:
- Build a causal model of the business as we want it to be. This can be done by subject matter experts.
- Analyze the causal model to help us understand which data is the most important.
- Analyze our historic data to see how much of the causal model can be expressed without adding more data sources. If something is missing, we need to decide whether to try and find the needed data or reduce the scope of the solution. We might also discover new causal relationships in the data that we need to add to our causal model.
Iterate steps 1-3 until we’re satisfied with the model. Note that we can start at steps 1 or 3. - Build functions that fulfill each of the cause-and-effect relationships. Some of these functions will be very simple and some will involve sophisticated ML or DL algorithms.
- Deploy the AI driven solution that embeds the above functions.
- Monitor the solution as it runs in our newly transformed business and feedback any improvements.
In this blog post, we’ll take a more detailed look at each of these steps. Note that the goal is not to provide an overview of how to do causal modeling – that will be the subject of future posts. Our focus here is how to approach a digital transformation project using Geminos Causeway.
We’ll use the same example throughout, which is a simplified version of a sustainable supply chain solution we’re working on for the CPG industry. This particular use case is for palm oil, but a lot of the same issues apply to other commodities, such as coffee, tea and rubber. Palm oil sustainability is a particularly difficult problem since palm oil is four to ten times as efficient as other vegetable oils in terms of land usage. However, it’s mostly grown in tropical areas such as Malaysia and Indonesia, which has led to significant problems, such as deforestation, peat burning and forced labor. The major CPGs have set ambitious goals to remove these problems from their supply chains, but the fact is that the underlying problems are extremely complex and not very amenable to traditional data science.
Causal modeling has the potential to enable major CPGs to achieve these ambitious goals by providing a much deeper understanding of the various problems. It can also help to provide better insights into the potential responses and interventions available to CPGs.
1. Build a causal model of the business as we want it to be
To build a causal model for a given use case, we start by identifying the events that affect the business that we want to digitally transform and then think about the effects that are caused by those events.
At this stage, all we need to do is to draw a causal diagram that shows the cause-and-effect relationships. Note that this first step is based only on subject matter expertise. We’ll refine the model later by looking at historical data.
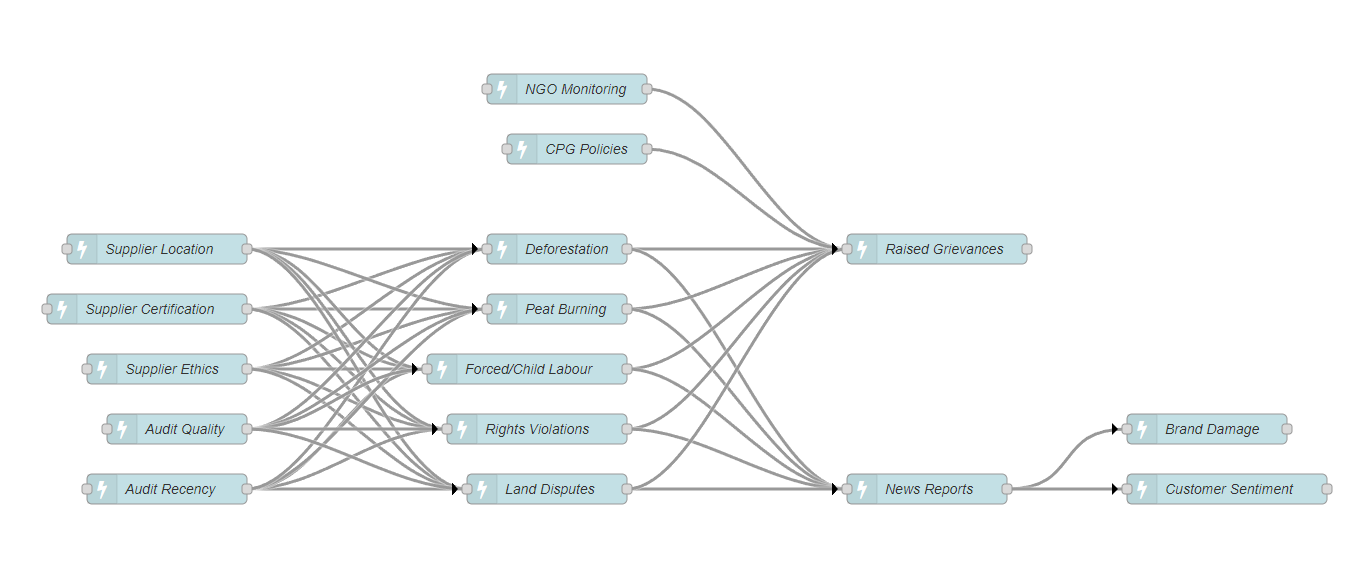
Note that this is a simplified causal model, significantly cut back from the one we used to build the actual palm oil solution.
The key difference between causal and more traditional modeling is that we’re not building a flow chart – we’re looking for events/variables and the effects they cause and we don’t show positive and negative outcomes separately. For example, Supplier Location could have a positive or negative effect on Deforestation (e.g., the Supplier might be in an area that has already been deforested or it might be in an untouched, heavily forested area). This is fundamental and allows us to use Pearl’s causal calculus to analyze the model in subsequent steps.
It’s also important to understand that some of our ‘events’ can take a range of values over time (i.e., they might have some kind of statistical distribution, such as normal or Gaussian) and the effect they cause might also have a distribution. Fans of Bayesian networks will see that causal modeling is an extension of Pearl’s earlier work in that area.
As we’re working on the Causal Model (CM), we’ll also start to develop the related Knowledge Model (KM), which shows the various entities, attributes and relationships that are involved in our use case. You can think of the KM as capturing the static relationships between things involved in the business process, while the CM captures the dynamics. Geminos Causeway stores both of these models in a single repository that uses a powerful graph database.
2. Analyze the Causal Model
Geminos Causeway includes powerful analytics, based on Pearl’s causal calculus, that help us to understand the most important causal paths in a given model.
The first step is to decide which outcome we’re interested in – e.g., let’s focus our initial efforts on Raised Grievances. We then need to pick a ‘treatment variable’ that we might be able to change in order to affect a change in the outcome. Supplier Certification is one possible choice in our palm oil model.
The analytics built into Causeway can then be used to check all of the potential paths between the treatment and the outcome, highlighting important aspects such as back door paths that go the ‘wrong way’ through the causal model and must therefore be blocked. The end result is a much better understanding of the cause-and-effect relationships and the data we need in order to fulfill the key paths between the treatment and the outcome.
Note that this is quite different to the current data science practice of looking for correlations between the variables in our data. The ‘causal science’ approach starts by identifying the actual causal paths and then only looking at the data that’s necessary to understand those paths.
A separate blog post will go into a lot more detail on this topic.
3. Analyze Historical Data
The entirety of the first two steps can be completed by business analysts and SMEs. We now need to delve into the historical data to fill out as much of the causal model as possible, while recognizing that there are likely to be some gaps.
This step will probably require a data analyst and maybe a data scientist.
Note that it’s OK at this stage for there to be differences between the causal model and what we find in the historic data. Bear in mind that the causal model expresses the new, digitalized world that we want to create, so data gathered from our existing operations may not contain everything we need. Also, we might have missed a few things when we built our causal model. Thinking through these various gaps and expanding or descoping the causal model, and/or finding new data sources is an important part of the process.
Geminos Causeway includes powerful, easy to use tools to populate the CM and KM with data and to analyze the data using causal calculus.
4. Iterate Steps 1-3
No causal model is perfect – it is, after all, a model of the real world. However, a few iterations through steps 1 to 3 will help us to more fully understand the dynamics of the business process and to ensure we have the data needed for the model to work.
As is the case with most iterative processes, this one doesn’t always start cleanly by building a model and then looking at the data. In reality, most projects will start with some understanding of the data and begin by building a model from that. Geminos Causeway provides comprehensive support no matter where you want to start.
Using Geminos Causeway, we also have the luxury of using the underlying causal science to monitor our digital transformation solution as it’s actually running (see step 7), thereby giving us the opportunity to improve results over time. As a result, we don’t need to strive too hard for perfection in the modeling phase.
5. Build functions for each cause-and-effect relationship
Once we’re happy with the causal and knowledge models, we need to build the required data science models. This step is where causal science and data science truly intersect.
Each effect event needs a function effect = f (cause1…causen) that expresses the cause-and-effect relationship. In some cases, this is a simple workflow – i.e., if the cause event happens, then take the effect action. However, in more complex cases, we may need to use Machine Learning (ML) or Deep Learning (DL) to understand the causal relationship. There’s a whole spectrum of levels of complexity in between these two extremes, including human decisions that are augmented with AI.
By taking this approach, we move away from the monolithic algorithms traditionally used in AI, using the causal model to break the problem down into a series of simpler steps.
The end result is model of our digitalized business that is much easier to understand and implement, and also much more transparent (“AI That Knows Why”). In addition, parts of the model can be easily separated out and reused in other use cases that rely on the same cause-and-effect structures.
6. Build the solution
Geminos Causeway is built into the established low/no-code Node-RED platform. This means we inherit Node-RED’s highly scalable, cloud-agnostic, containerized solution architecture, together with thousands of nodes for data input/output and general functionality (including most AI algorithms and platforms). It’s therefore easy to build and deploy a complete solution at scale that encompasses the causal models.
The end result is a low/no-code environment for the creation of highly scalable and sophisticated AI driven solutions.
7. Monitor the solution as it runs and feedback improvements into the model
Because the solution is directly based on the causal model, Geminos Causeway is able to build monitoring into the system and gather statistics about, for example, the frequency of each event and the number of times a given causal path is traversed as a result. These stats can be fed directly back into the model and therefore looped back into the solution. As a result, the solution can be improved over time..
Summary
Different communities have approached Pearl’s work on causality from a number of different angles, such as gaining a better understanding of data (e.g., in epidemiology), risk management, systems control and Artificial General Intelligence.
At Geminos, we are 100% focused on bringing the benefits of Pearl’s work to the development of everyday AI-driven business solutions. To make that possible, our platform merges causality with traditional data science and includes low/no-code capabilities to ease the creation of finished solutions.
About the Author
Stu Frost – Founder & Chief Executive Officer (CEO)
Stu FrostStu has 30 years’ experience in founding and leading successful data management and analytics startups. He founded SELECT Software Tools at age 26 and led the company as CEO through rapid growth and expansion, including a very successful NASDAQ IPO in 1996. He then founded DATAllegro in 2003 which was acquired by Microsoft in 2008 for $275m. As part of the acquisition, Stu joined Microsoft to lead the data warehousing group, which generated around $1bn in revenue. After leaving Microsoft in 2010, he created and incubated some of the leading companies in the Industrial Internet of Things (IIoT) market, including Maana (IIoT knowledge platform), OspreyData (oil and gas analytics), NarrativeWave (wind farm analytics), PingThings (electricity grid analytics) ThinkIQ (food traceability) and SWARM (AI agents for complex industrial problems). During this time, he saw the market go from its very early gestation to the point where major industrial companies are starting to make significant, long term commitments to digitization. Through this unique experience, Stu has developed deep knowledge of the market’s needs and how to successfully create and sell key technologies to meet those needs.
Information About Forward-Looking Statements:
This document may contain “forward-looking statements” – that is, statements related to future, not past, events. In this context, forward-looking statements often address our expected future business and financial performance and financial condition, and often contain words such as “expect,” “anticipate,” “intend,” “plan,” “believe,” “seek,” “see,” “will,” “would,” “could” or “target.”
While these forward-looking statements represent our current judgment on what the future holds, uncertainties may cause actual future results to be materially different than those expressed in our forward-looking statements. Because these forward-looking statements reflect only opinions as to uncertain future events, we do not undertake to update our forward-looking statements.